
目录[-]
前言
分类(Classification)是数据挖掘领域中的一种重要技术,它从一组已分类的训练样本中发现分类模型,将这个分类模型应用到待分类的样本进行预测。
当前主流的分类算法有:朴素贝叶斯分类(Naive Bayes)、支持向量机(SVM)、KNN(K-Nearest Neighbors)、神经网络(NNet)、决策树(Decision Tree)等等。
KNN算法是一个理论上比较成熟的方法,最初由Cover和Hart于1968年提出,思路非常简单直观,易于快速实现。
基本思想
如下图所示,假设有已知类型的三类训练样本 $ \omega_1、\omega_2、\omega_3$,现对样本 $ X_u $进行分类。根据距离函数依次计算待分类样本 $ X_u$ 和每个训练的距离,这个距离看做是相似度。选择与待分类样本距离最近的K个训练样本,如下图黑色箭头所指的5个样本。最后K个类别中所属类别最多的类别作为待分类样本的类别,如下图中 $ X_u $属于 $ \omega_1$ 类。
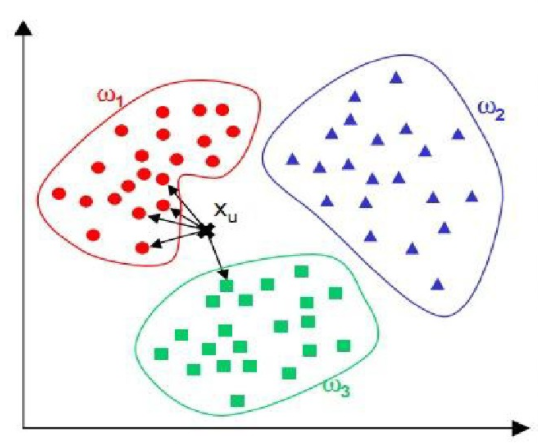
KNN可以说是一种最直接的用来分类未知数据的方法。简单来说,KNN可以看成:有那么一堆已经知道类别的数据,当有一个新数据进入时,依次计算这个数据和每个训练数据的距离,然后跳出离这个数据最近的K个点,看看这个K个点属于什么类型,然后用少数服从多数的原则,给新数据归类。
算法实现
实现步骤
- 1.构建训练数据集(数据标准化);
- 2.计算训练数据集中的点与当前点的距离;
- 3.按照距离递增排序;
- 4.选取距离与当前距离最小的K个点;
- 5.确定前K个点中所在类别的出现概率;
- 6.返回前K个点中出现概率最高的类别作为当前点的分类。
Python实现代码:
import numpy as np
import operator
def createDataSet():
"""
构造假的训练数据,产生四条训练样本,group为样本属性,labels为分类标签,即[1.0,1.1]属于A类
:return:
"""
group = np.array([[1.0, 1.1], [1.0, 1.0], [0, 0], [0, 0.1]])
labels = ['A', 'A', 'B', 'B']
return group, labels
def classify(inX, dataSet, labels, k):
"""
简单KNN分类
:param inX: 待分类向量
:param dataSet: 训练样本集
:param labels: 训练样本标签
:param k: K值
:return:
"""
dataSetSize = dataSet.shape[0] # 训练样本个数
diffMat = np.tile(inX, (dataSetSize, 1)) - dataSet # 计算训练样本和待分类样本的数值差值
# 用于后面计算欧式距离,欧氏距离为各维度上数值差值的平方和再开方的结果
sqDiffMat = diffMat ** 2 # 差值的平方
sqDistances = sqDiffMat.sum(axis=1) # 平方和
distances = sqDistances ** 0.5 # 平方和开方
sortedDistIndicies = distances.argsort() # 返回升序排列后的索引
classCount = {}
# 统计前K个样本中各标签出现次数
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]
classCount[voteIlabel] = classCount.get(voteIlabel, 0) + 1
sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True)
# 按标签次数排序,返回次数最多的标签
return sortedClassCount[0][0]
if __name__ == '__main__':
group, labels = createDataSet()
print(classify([0, 0], group, labels, 2))
# 最终输出类别为B
上例代码中,样本距离计算采用的是欧式距离,距离方法的选择也会影响到分类结果,关于可选的距离度量以及计算公式,可以参考这篇文章 常用样本相似性和距离度量方法。
优缺点
-
优点
- 1.KNN算法思想简单,非常容易实现;
- 2.有新样本要加入训练集时,无需重新训练;
- 3.时间和空间复杂度与训练集大小成线性相关;
-
缺点
-
1.分类速度慢;
KNN算法的时间复杂度和储存空间会随着训练集规模和特征维数的增大而增加。因此每次分类新样本时,都要和所有的训练样本进行计算比较。整个算法的时间复杂度可以用 $O(m*n)$ 表示,其实 $m$ 和 $n$ 分别是特征维度和训练集样本个数。
-
2.各属性权重相同,影响准确率;
当样分布不均匀时,如果某一个类的样本容量很大,而其他类样本容量很小。有可能在对新样本进行分类时,前K个最近的样本中样本容量大的类占了多数,而不是真正接近的类占了多数,这样会导致分类错误。
-
3.样本依赖性很强;
- 4.K值不好确定;
K值设置过小时,得到的邻近数也会太小,这样会放大噪声数据的干扰,影响分类精度。K值设置过大时,就会使2中描述的错误概率增加。
-
KNN改进
降低计算复杂度
KNN的一个严重问题就是需要储存全部训练样本,以及繁重的距离计算量。下面是一些已知的改进方法:
-
特征维度压缩
在KNN算法之前对样本属性进行约简,删除对分类结果影响较小(不重要)的属性。例如粗糙集理论在用于决策表的属性约简时,可在保持决策表中决策能力不变的前提下,删除其中不相关的冗余属性。
-
缩小训练样本
就是在原样本中挑选出对分类计算有效的样本,使样本总数合理地减少,但又不会影响分类精度。常用的有剪辑近邻法和压缩近邻法。
-
剪辑近邻法
其基本思想是:利用现有样本集对自身进行剪辑,将不同类别交界处的样本以适当方式筛选,可以实现即减少样本数,又提高正确识别率的目的。过程如下:将样本集 $K^N$ 分成两个相互独立的子集: test集 $K^T$ 和reference集 $K^R$ 。首先对 $K^T$ 中每个样本 $X_i$ 在 $K^R$ 中找到其最近邻的样本 $Y_i(X_i)$ 。如果 $Y_i$ 和 $X_i$ 不属于同一类别, 则将 $X_i$ 从 $K^t$ 中删除,最后得到一个剪辑的样本集 $K^TE$ ,以取代原样本。
-
压缩近邻法
其基本思想是:利用现有样本集,逐渐生成一个新的样本集,使该样本在保留最少样本的条件下,仍能对原有样本的全部用最近邻法正确分类。过程如下:定义两个储存器,一个用来存放即将生成的样本集,称为Store;另一个储存器则存放原样本,称为Grabbag。算法过程:
过程1.初始化,Store是空集,原样本存入Grabbag;从Grabbag中任意选择一样本放入Store中,作为新样本集的第一个样本。过程2.样本集生成,依次从Grabbag中取出第 $i$ 个样本,用Store中的样本集用最近邻发分类。若分类错误,则将该样本从Grabbag中转入Store,若分类正确,则将该样本放回Grabbag。过程3.结束判断,如果Grabbag中所有样本在执行过程2时没有发生转入Store现象,或者Grabbag已为空,则算法结束,否则转入过程2。
-
-
预建立结构
常用的是基于树的快速查找,其基本思想是:将样本按邻近关系分解成组,给出每组的质心,已经组内样本至质心的最大距离。这些组又可以形成层次结构,即组又分子组,因而待识别样本可将搜索近邻的范围从某一大组,逐渐深入到其中的子组,直至树的叶节点所代表的组,确定其近邻关系。
提高分类准确度
-
优化相似度量
前面已经计算样本间的相似度量有很多,常用样本相似性和距离度量方法。基本上KNN算法都是基于欧氏距离来计算样本相似度,但这种方法认为各维度对分类贡献率是相同的,这回影响分类的准确度。因此也有人提出过基于权重调整系数的改进方法。改方法的思想是,在距离度量函数中对不同属性赋予不同权重,改进后的欧式距离公式为: $$d(x_i,y_j)=\sqrt{\sum_{k=1}^l\omega_l(x_{ki}-y_{kj})^2}$$ 然后通过灵敏度法确定权重向量 $\omega_l$。
- 首先统计出分类错误的样本数 $n$;
- 依次去掉特征集中的属性,应用KNN分类,统计出分类错误的样本数量 $n_q$;
- $n_q$与 $n$ 的比值 $n_q \over n$ 就是对于特征维度的权重系数。
-
选取恰当K值
由于KNN算法中几乎所有的计算都发生在分类阶段,而且分类效果很大程度上依赖于L值的选择,而目前为止,比较好的选择K值的方法只能是通过反复试验调整。